Language and Ontologies¶
Ontology terms¶
Terms which can be annotated with ontologies inherit from uid.models.DictBase
class, and are modeled in the uid.models.DictRole, uid.models.DictCountry
uid.models.DictSex, uid.models.DictUberon, uid.models.DictDevelStage,
uid.models.DictPhysioStage, uid.models.DictSpecie and uid.models.DictBreed
classes. These terms are linked to user data, so there could be only one ontology for
a certain terms. Each term instance has a label attribute, that is the text
value of the ontology term, and a term attribute which is the ontology id. The
ontology link can be formatted for BioSamples submission by setting the library_name
class attribute:
from uid.models import DictSex
male = DictSex.objects.get(label="male")
# prints 'PATO'
print(male.library_name)
# returns [{'value': 'male', 'terms': [{'url': 'http://purl.obolibrary.org/obo/PATO_0000384'}]}]
male.format_attribute()
The uid.models.DictSpecie class implement the general_breed_label and
the general_breed_term attribute, in which the general LBO ontology is
mapped for the specie level. This let to give at least the general breed ontology
for unmapped breed ontology through the uid.models.DictBreed class:
from uid.models import DictBreed, DictCountry
italy = DictCountry.objects.get(label="Italy")
breed = DictBreed.objects.get(country=italy, supplied_breed="Cinta Senese")
# returns [{'value': 'pig breed', 'terms': [{'url': 'http://purl.obolibrary.org/obo/LBO_0000003'}]}]
breed.format_attribute()
Ontology terms could be manually annotated by setting the confidence with the
CURATED value from Common confidences, or can be automatically annotated
by calling zooma.tasks
The language system¶
InjectTool can provide translations for species terms in order to translate common names, like dog, cow, etc in the corresponding scientific term, like Canis familiaris, Bos taurus, etc. In such way, data could be imported using the common names of the species in the language of the submission user. The relationship beetween models are illustrated in the following diagram:
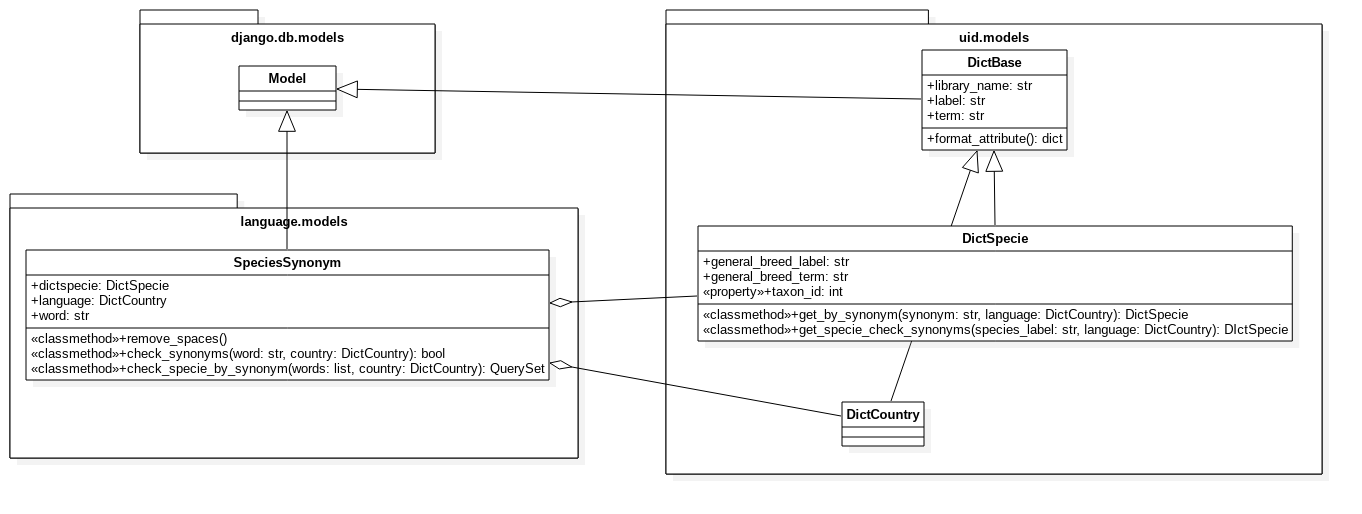
The language.models.SpecieSynonym class manage different species translation
relying on the relationships between uid.models.DictSpecie and
uid.models.DictCountry models. When an user load data from his datasource,
it requires to specify a uid.models.DictCountry object that will be
the default language used for translation. When the system found a specie, will
try to determine the correct uid.models.DictSpecie object relying on
user defined language (or on the default language) using the language.models.SpecieSynonym
foreing keys:
from uid.models import DictCountry, DictSpecie
from language.models import SpecieSynonym
english_language = DictCountry.objects.get(label="United Kingdom")
# test that "Dog" map to a species term
SpecieSynonym.check_specie_by_synonym("Dog", english_language)
# return a list of translations (SpecieSynonym instances) given a list of words.
# Note: returns only found translations:
SpecieSynonym.check_synonyms(["Dog", "Cattle", "foo"], english_language)
# get a specie object from a synonym:
specie = DictSpecie.get_by_synonym('Dog', english_language)
The language management is currently supported for species, but could be extended
even for other terms, like uid.models.DictUberon, uid.models.DictDevelStage,
and uid.models.DictPhysioStage.